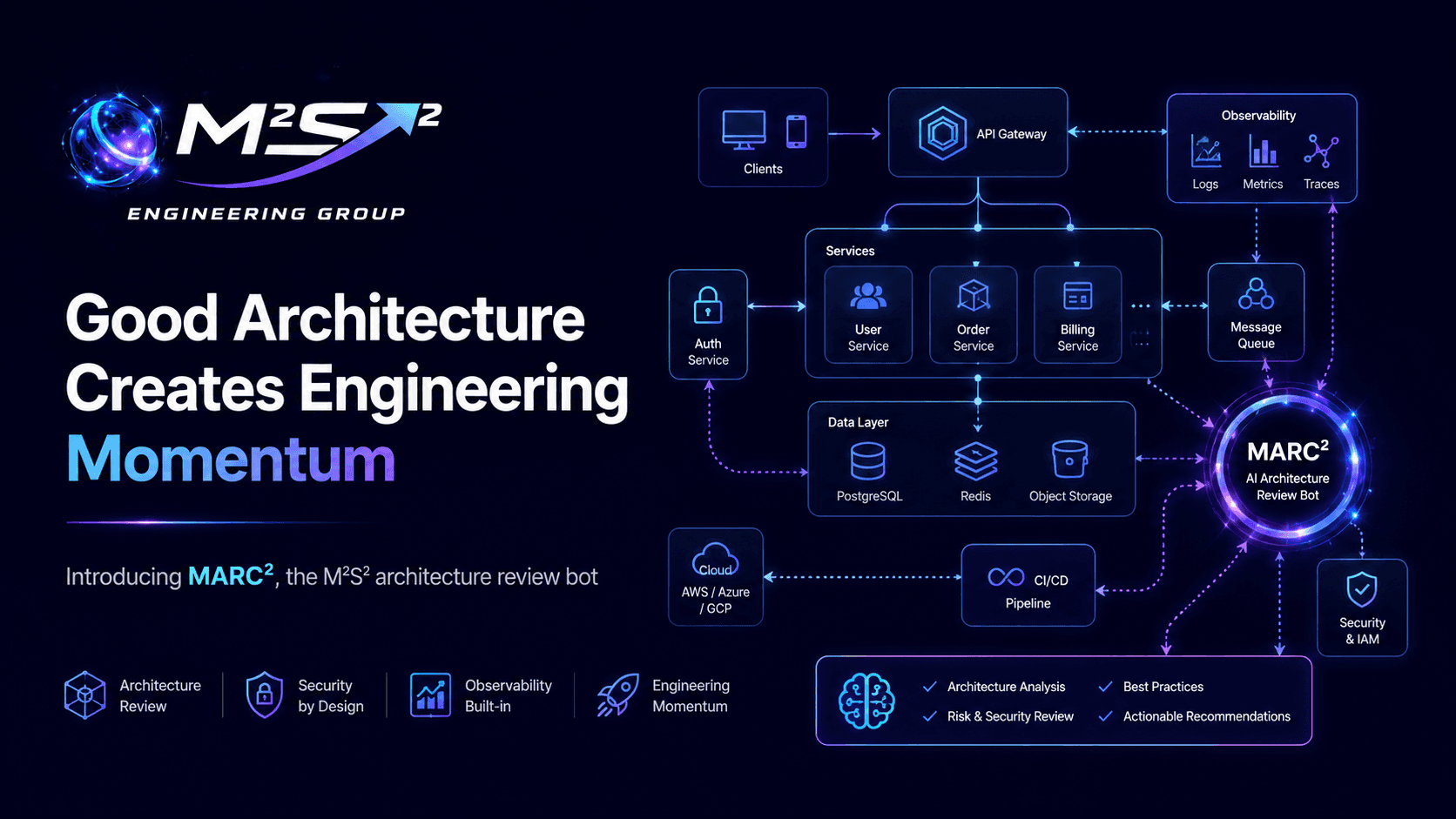
Good Architecture Includes Observability

Good architecture is not only about how a system is built. It is also about how well the team can understand that system once it is running.
That is where observability belongs in the architecture conversation.
It is common for observability to be treated as something that comes after the main engineering work. The service gets built. The API works. The deployment succeeds. Then, somewhere near the end, the team starts thinking about logs, dashboards, alerts, and operational visibility.
That approach creates a gap.
The architecture may look clean on paper, but once the system is in production, the team has to understand how it behaves under real conditions. Real users do not follow the happy path perfectly. Dependencies slow down. Queues back up. Data arrives in unexpected shapes. Deployments change behavior in ways that are not always obvious.
If the system does not give the team a way to see those things clearly, the architecture is incomplete.
Observability is not decoration around the system. It is part of the system design.
Architecture Describes the System. Observability Shows the Truth.
Architecture is built on assumptions.
During design, teams make reasonable guesses about usage patterns, service boundaries, dependency behavior, data flow, scale, latency, and failure modes. Some of those assumptions are based on experience. Some are based on current requirements. Some are simply the best call the team can make with the information available at the time.
That is normal.
The problem is not that architecture contains assumptions. Every architecture does.
The problem is when those assumptions cannot be tested once the system is real.
A design might assume that an external dependency will be reliable enough. Production may show that it is the slowest part of the request path. A queue might look like a clean decoupling point during design. Production may reveal retry behavior, duplication, or ordering concerns that were not obvious upfront. A serverless function might seem isolated and simple until timeouts, cold starts, and downstream limits begin shaping the user experience.
Observability is how the team learns what reality looks like.
Without it, production becomes a black box. The team may know something is wrong, but not where. They may see failures, but not the path that produced them. They may know customers are impacted, but not which customers, how often, or why.
That is not just an operations problem.
It is an architecture problem.
If the team cannot understand how the system behaves in production, the design is missing a critical feedback loop.
Observability Is More Than Having Logs
A lot of systems have logs. Far fewer systems are actually observable.
I have seen versions of the same story play out more than once. A team ships a feature, the deployment succeeds, and the basic dashboards look fine. Then support reports that a subset of users cannot complete a workflow. The application has logs, but the logs only show isolated fragments. One service logged the request. Another logged a timeout. A third recorded a retry. Somewhere downstream, a dependency returned an unexpected response.
Nothing is completely invisible, but nothing is connected well enough to explain the full story.
That is the pitfall.
Teams do not need more disconnected data. They need enough context to move from symptom to cause.
Good observability connects the signals that matter. It helps engineers follow the path of a request, understand where latency was introduced, see which dependency shaped the outcome, and determine whether the issue is isolated or systemic. It reduces the need to rely on memory, guesswork, or the one person who happens to know that part of the system best.
Logs matter. Metrics matter. Traces, dashboards, and alerts matter too. But the toolset is not the point. The point is whether the team can ask useful questions about the system and get useful answers.
Dumping logs into a platform does not automatically create understanding. Generic CPU and memory metrics may tell you something about infrastructure health without telling you much about user impact. Dashboards can look impressive while answering very little. Alerts can wake people up without giving them enough context to act.
The goal is not more data.
The goal is better understanding.
That is why observability has to be designed intentionally.
Observability Changes How Teams Work
The most obvious benefit of observability is faster debugging, but that is not the only benefit.
The larger benefit is that observability changes the way teams make decisions.
When a system is difficult to observe, conversations tend to become speculative. People rely on memory, intuition, and whatever signal is easiest to find. During incidents, that can create stress and confusion. After incidents, it can lead to shallow conclusions because the team never had a clear enough view of what actually happened.
When a system is observable, the conversation changes.
The team can look at the request path instead of debating which service might be slow. They can separate a deployment issue from a data issue. They can see whether a failure affected one customer, one workflow, or the entire system. They can understand whether a dependency is occasionally slow or consistently shaping the user experience.
That kind of visibility creates better engineering behavior.
Teams move from guessing to investigating. They move from opinion to evidence. They move from “it seems fine” to “here is what the system is telling us.”
That feedback loop matters beyond incidents. It helps teams improve architecture over time. It shows where the system is under stress. It reveals dependencies that are more fragile than expected. It exposes workflows that are harder to support than they looked during design.
Observability does not make systems simple, but it does make complexity easier to see.
Visible complexity is much easier to manage than hidden complexity.
Observability Should Be Designed Early
Observability is much harder to add after the fact.
Once a system is already built, teams often discover that the information they need was never captured. The logs are inconsistent. Trace context does not cross service boundaries. Metrics describe infrastructure health but not business impact. Alerts fire too late, too often, or without enough detail to act on.
At that point, improving observability becomes another project layered on top of the original system.
It is much easier to build visibility into the system while the architecture is still being shaped.
That does not mean every project needs an elaborate observability platform on day one. It means the team should think about how the system will be understood once it is running. Critical workflows should leave a trail. Risky dependencies should be measurable. Failure modes should produce useful signals. The team should be able to tell whether the system is healthy from both a technical and user perspective.
This becomes especially important as systems become more distributed.
The more services, queues, functions, APIs, and third-party dependencies involved, the more important it becomes to preserve context across the flow. Without that context, every incident becomes a scavenger hunt across logs, dashboards, cloud consoles, and Slack messages.
That scavenger hunt costs time, confidence, and momentum.
The Best Signals Connect to Real Impact
Not every signal is equally useful.
A team can collect hundreds of metrics and still struggle to understand whether users are having a good experience. A dashboard can show that infrastructure is healthy while a critical workflow is failing. An alert can be technically correct and still provide little value if it does not explain what is impacted or why anyone should care.
Good observability connects technical behavior to real impact.
Latency is not just a performance number; it represents a user waiting on the system. Error rates are not just percentages; they are workflows that did not complete. Queue depth is not just an operational metric; it is a sign that work is backing up somewhere in the system. Dependency failures matter because they change how gracefully the application can recover, degrade, or protect the user experience. Deployment events matter because every release changes the behavior of the system in some way, even when the deployment itself succeeds.
The best signals help a team understand what is happening in terms that matter to both engineering and the business.
This does not make infrastructure metrics unimportant. They are part of the picture. But they should not be the whole picture. Teams also need visibility into critical workflows, service boundaries, external dependencies, and the outcomes customers actually experience.
A healthy architecture makes those relationships easier to see.
Observability Belongs in Architecture Reviews
This is why observability belongs in architecture reviews.
A design review should not stop at whether the components fit together. It should also consider how the system will be operated, supported, and improved once it is real.
That conversation changes the quality of the architecture.
It forces the team to think about where risk exists. It brings critical workflows into focus. It exposes dependencies that may need better monitoring or fallback behavior. It encourages teams to think about how they will diagnose failure before failure happens.
This is also where MARC², the M²S² architecture review bot, can help start the conversation.
A first-pass architecture review should surface more than service boundaries, data flow, and scaling assumptions. It should also help identify whether the system gives the team enough visibility to understand it in production.
MARC² is not a replacement for experienced judgment, but it can help reveal where observability may be missing from the design conversation.
That is a useful starting point.
Observability Is Part of Engineering Momentum
Engineering momentum depends on a team’s ability to keep moving without constantly losing time to avoidable confusion.
When observability is weak, teams lose time reconstructing context. Incidents take longer because the system does not clearly show where the problem started or how far the impact spread. Releases feel riskier because there is not enough confidence in how the system changed after deployment. Architecture decisions become harder to validate because the team has limited feedback from production.
That uncertainty affects more than engineering. Leaders have less confidence in what is happening. Product conversations become harder to ground in reality. Teams spend more energy interpreting symptoms than improving the system.
Strong observability creates a better feedback loop. It helps teams see how the system behaves, where pressure is building, and which decisions need to be revisited. It gives engineers and leaders a shared understanding of the system as it actually runs, not just as it was designed.
That is why observability is not just an operational concern.
It is part of good architecture.
The code matters. The services matter. The deployment model matters. The data model matters. But the team’s ability to understand and reason about the system in production is the most important thing.
A system that cannot be understood in production cannot be confidently operated.
And a system that cannot be confidently operated will eventually slow the team down.
Good architecture includes observability because good architecture is not only about building the system. It is about building a system the team can understand, operate, and improve.
That is what keeps momentum alive.
From Visibility to Momentum
If your team is designing a new system, preparing for launch, or trying to understand why an existing platform has become harder to operate, observability is a good place to look.
The question is not simply whether you have logs, metrics, traces, dashboards, or alerts. The better question is whether your team can understand what the system is doing when it matters most.
That is the kind of visibility good architecture should provide.
MARC², the M²S² architecture review bot, can help start that conversation by surfacing architecture and observability gaps early. From there, M²S² can help your team reason through the tradeoffs, improve the design, and build the feedback loops needed to keep moving with confidence.
MARC² can help you start the conversation. M²S² can help you turn it into action.